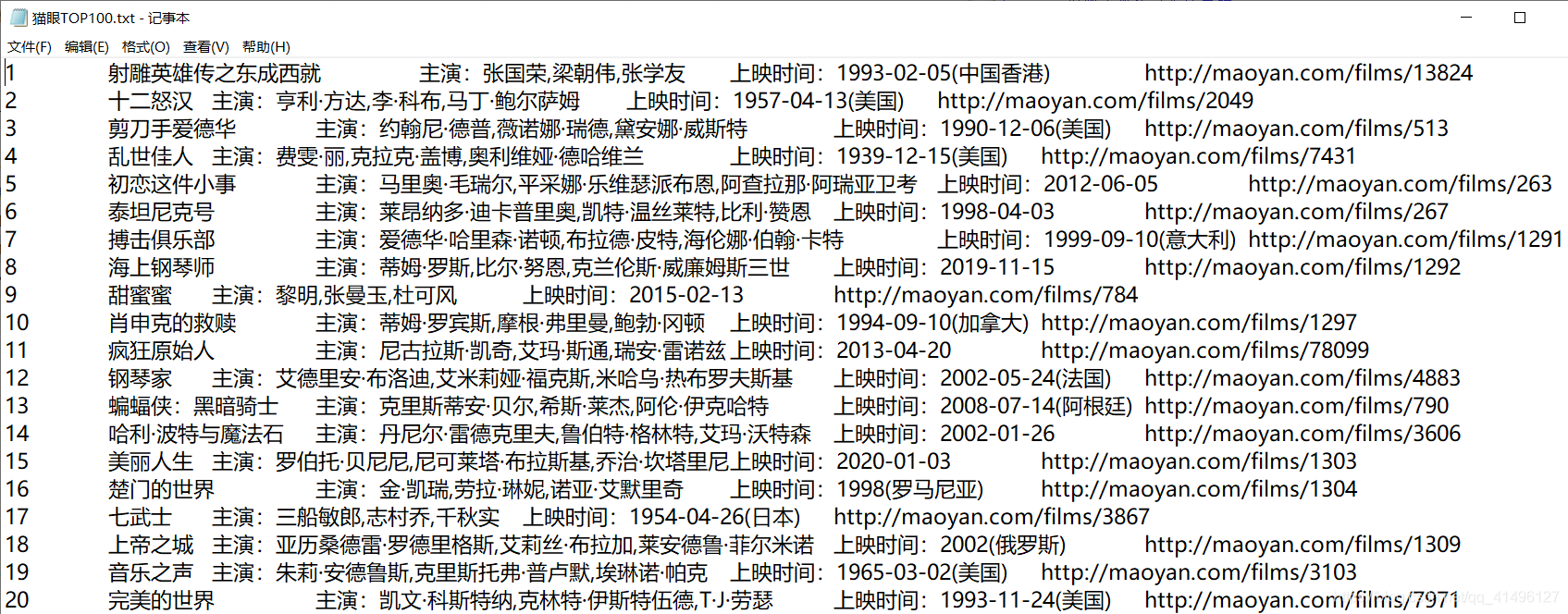
Python爬取猫眼电影TOP100榜
兴趣点:
这个没什么特别的兴趣,只是单纯爬猫眼练手的人太多了,所以我也打算加入他们,对猫眼员工说一声不好意思了,哈哈哈!
爬取网址:
传送门:https://maoyan.com/board/4
爬虫大体思路及方法:
大体思路:
(1)TOP100榜共10页,每页10部电影,他们的文本和电影专页链接就是我们的目标
(2)我们先把这10页网页的URL链接获取出来,放到一个列表里
(3)利用循环读取每个网页中的每个电影的相关信息(姓名,主演,上映时间,链接),读入一个列表,直接写入txt文件
方法:
(1)页面获取方法:getHTMLText(url)
(2)把10页网页的URL存入列表:fillList(url,pagelist)
(3)获取并保存相关信息:getAndSave(pagelist,path)
参数解读:
(1)pagelist:存储10页网页的URL的列表
(2)path:本地存储路径
部分细节讲解:
(1)我这两天可能是爬猫眼的次数有点多了,IP被限制了,访问会弹出“美团验证”,这样我的爬虫就访问不到目标网页了(;′⌒`),网上找到的方法就是在headers里加一个Cookie:
(2)页面规律:可以发现第一页是?offset=0
真实url获取:
url = "https://maoyan.com/board/4?offset="
for i in range(10): #共10页
new_url = url + "{}".format(i*10)(3)txt文件打开我放在了循环的外面,感觉放在循环里一直开关怪怪的……,记得读取方式是“a”,否则每次 write 都会覆盖之前内容,还有——记得关闭文件
(4)每个电影区域规律:dd标签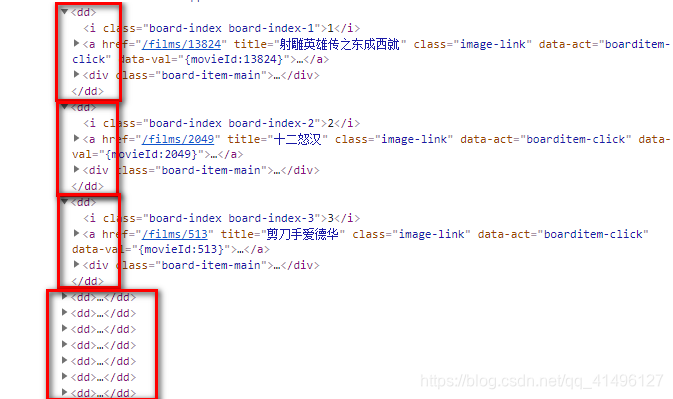
(5)再次强调字符串的去空格:str.strip()
完整代码:
import requests
import re
import os
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
kv = {
"user-agent":"Mozilla/5.0",
"Cookie": "__mta=150238857.1602895907970.1602895907970.1602895907970.1; uuid_n_v=v1; uuid=EF37CF40101211EBA49537871E07CB9B551E0E6AAAD0496CB9577D92C804414F; _csrf=48c1a11d90da9b55c99273c2bbc35e938aec46d79119cc219fd139828fd29bde; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1602895908; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1602895908; _lxsdk_cuid=175340a8c37c8-02b1af385c3412-5373e62-144000-175340a8c373c; _lxsdk=EF37CF40101211EBA49537871E07CB9B551E0E6AAAD0496CB9577D92C804414F; _lxsdk_s=175340a8c39-48c-9f6-8fe%7C%7C2"
}
r = requests.get(url,headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("getHTMLText失败!")
return ""
def fillList(url,pagelist):
for i in range(10):
new_url = url + "{}".format(i*10)
pagelist.append(new_url)
def getAndSave(pagelist,path):
with open(path,'a',encoding = 'utf-8') as f:
for page in pagelist:
html = getHTMLText(page)
soup = BeautifulSoup(html,"html.parser")
for dd in soup.find_all('dd'):
plist = []
for p in dd.find_all('p'):
plist.append(p.string)
f.write(dd.i.string + '\t' + plist[0].strip() + '\t' + plist[1].strip() + '\t' + plist[2].strip() + '\t' + 'http://maoyan.com' + dd.p.a['href'] + '\n')
print(dd.i.string + "\t" + plist[0].strip())
f.close()
def main():
pagelist = []
url = "https://maoyan.com/board/4?offset="
path = "猫眼TOP100.txt"
fillList(url,pagelist)
print("fill成功")
getAndSave(pagelist,path)
print("save成功")
main()运行状态与结果: